Routing
The routing is the function of searching for a path among all the possible in a packet network whose topologies have a great connectivity
Given that it's about finding the best possible route and in consequence what is the metric that should be used to measure it
The network must find a route using:
- Efficiency
- Flexibility
The switches of the network are organised in a tree structure
Routing static uses the same approach all the time
The routing dynamic allows for changes in routing depending on traffic
Uses a structure of relationship peer-to-peer nodes
Criteria of routing
Routing alternative
Of the possible routes between two central end are predefined
It is the responsibility of the switch source to select the appropriate route for each call
Each switch has a set of pre-set routes, in order of preference
A different set of routes preplanificadas in moments different of time
Two types:
- Alternative fixed
Only a sequence of routing for each couple source-destination - Alternative dynamic
Different set of routes preplanificadas in moments different of time
Routing in packet-switched networks
One of the most complicated and crucial aspects of the design of packet-switched networks is related to the routing
Features required:
- Accuracy
- Simplicity
- Robustness
- Stability
- Impartiality
- Optimization
- Efficiency
Performance criteria
It is used for the choice of a route
Two fundamental techniques:
- Choosing the path with the fewest hops: Minimize network resource consumption
- A generalization of the above is the criterion of the minimum cost
- In case of different link costs, the path that is the minimum cost will be taken
- If each node has equal cost, we can generalize this criterion by looking for the path of least number of hops
Moment and place of decision
- Instant
- Packet or datagram
If costs change, the next packet can follow a different route, again determined by each node along the way - Virtual circuit
Each node remembers the routing decision made when the virtual circuit was established, so that it is limited to transmitting packets without making new decisions
- Packet or datagram
- Place
- Routing distributed
- Is carried out for each node
- It is the most robust
- Routing centralized
- Routing from the source
- Routing distributed
Source of information on the network and time of update
Routing decisions are usually made based on network knowledge, load, and link cost (but not always such as flooding and random routing)
- Routing distributed
- Nodes make use of local information (cost associated with each output binding)
- They can use information from adjacent nodes (congestion between them)
- Can get information from all nodes on a potential route of interest
- Routing central
- Collect information from all nodes
- Update time
- When the nodes have updated information of the network
- For a static routing strategy, the information is never updated
- For an adaptive technique, the update is carried out periodically
Strategies of routing ARPANET
First generation: 1969
- Adaptive algorithm distributed
- Estimation of the delays as a criterion of operation
- Algorithm of Bellman-Ford
- Each node exchanges its vector of delay with all of its neighbors
- Table routing updated based on the input information
- It does not take into account the speed of the line, but the length of the tail
- The length of the tail is not a good measure of the delay
- Responds slowly to congestion
Second generation: 1979
- It makes use of the delay as performance criterion
- The delay is measured directly
- Algorithm of Dijkstra
- It is good in low loads or moderate
- In the face of high loads, there is little correlation between the indicated and experienced delays
Third generation: 1987
- Change the estimates of the cost of the link
- Average delay measurement in last 10 seconds
- It is normalized on the basis of the current value and previous results
Strategies of routing
Routing static
A single-path permanent for each pair of nodes source-destination in the network
Determining the routes by using either of the algorithms of routing for minimum cost
Routes are fixed, at least as long as the network topology is
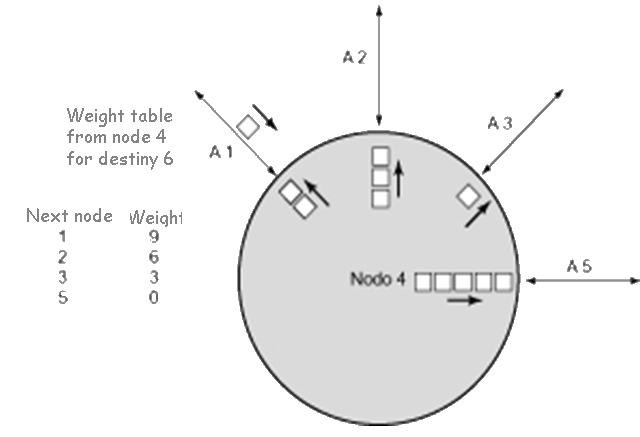
Example of routing static
Matrix routing central
{\tiny\text{Destination node}}\overset{\text{Source node}}{\begin{pmatrix}& 1& 2& 3& 4& 5& 6 \\ 1& & 1& 5& 2& 4& 5 \\ 2& 2& & 5& 2& 4& 5 \\ 3& 4& 3& & 5& 3& 5 \\ 4& 4& 4& 5& & 4& 5 \\ 5& 4& 4& 5& 5& & 5 \\ 6& 4& 4& 5& 5& 6 \\ \end{pmatrix}}
| Node Table 1 | |
| Destination | Following node |
| 2 | 2 |
| 3 | 4 |
| 4 | 4 |
| 5 | 4 |
| 6 | 4 |
| Table of Node 2 | |
| Destination | Following node |
| 1 | 1 |
| 3 | 3 |
| 4 | 4 |
| 5 | 4 |
| 6 | 4 |
| Node 3 table | |
| Destination | Following node |
| 1 | 5 |
| 2 | 5 |
| 4 | 5 |
| 5 | 5 |
| 6 | 5 |
| Node Table 4 | |
| Destination | Following node |
| 1 | 2 |
| 2 | 2 |
| 3 | 5 |
| 5 | 5 |
| 6 | 5 |
| Node 5 table | |
| Destination | Following node |
| 1 | 4 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 6 | 6 |
| Node Table 6 | |
| Destination | Following node |
| 1 | 5 |
| 2 | 5 |
| 3 | 5 |
| 4 | 5 |
| 5 | 5 |
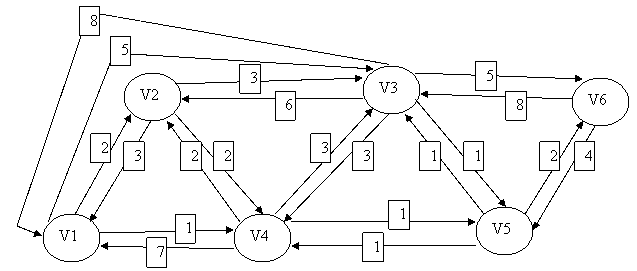
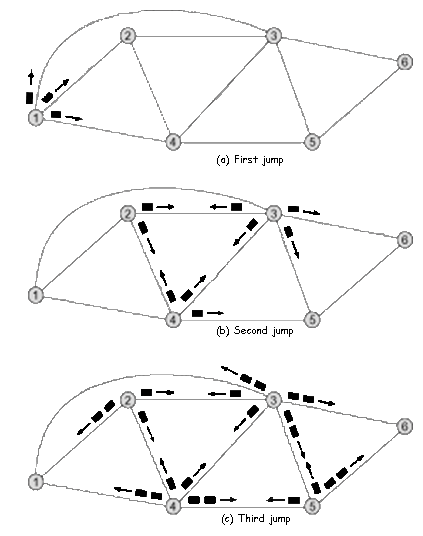
Flooding
It does not require any information about the network. A source node sends a packet to all its neighbor nodes. Neighboring nodes, in turn, transmit it over all output links except the one that arrived. Finally, a number of copies will arrive at the destination
Each packet contains a unique identifier, so duplicates can be discarded. In this way, one technique would be for nodes to be able to remember the identity of the packets they have previously retransmitted, so that network loads are avoided
Another simpler technique is that a hop count field can be included in each packet, a lifetime where each time a node transmits a packet, it decrements the count by 1, so that when the counter reaches the zero value of remove the packet from the network
Properties
- All possible paths between the source and destination nodes are tested. What offers us robustness
Example: Sending a high priority message to ensure that the package is received - At least one copy of the packet to be received at the destination will have used a lower hop path. It could be used initially to establish the route for a virtual circuit
- All nodes are visited. It can be useful to carry out the propagation of relevant information for all nodes (for example, a central routing table)
Example of flood
Routing random
A node selects a single outbound path to retransmit an incoming packet. Selection can be done randomly or alternately
An improvement is that you can select the output path in accordance with the calculation of probabilities
You do not need to use information about the network. In general, the route will not correspond to the one with the least cost or the one with the fewest number of jumps. It has less traffic than Flooding but is equally simple and robust. A node selects a single outgoing path to retransmit an incoming packet. Selection can be done randomly or alternately
An improvement is that you can select the output path in accordance with the calculation of probabilities
You do not need to use information about the network. In general, the route will not correspond to the one with the least cost or the one with the fewest number of jumps. It has less traffic than the flood one but is equally simple and robust
Routing adaptable
Virtually all packet-switched networks used some kind of technique of transmission adaptive
Routing decisions change as network conditions change:
- Failures
- Congestion
It requires information about the state of the network presenting disadvantages:
- Decisions are more complex: higher processing cost at network nodes
- It is necessary for the nodes to exchange information about the status and traffic of the network: increased traffic and degradation of network performance
- The reaction too quickly can cause oscillation or be too slow to be relevant
Advantages of routing adaptive
- Improvement of the performance
- It is helpful in the control of the congestion
- Complex system: Theoretical benefits may not be met
Classification
Classification made in accordance with the source of the information
- Local (isolated)
- Route the packet to the output link with the tail shorter
- You can include a weight for each destination. They are rarely used, since they do not easily exploit the information available
- Adjacent nodes
- All nodes
Example of routing adaptive isolated