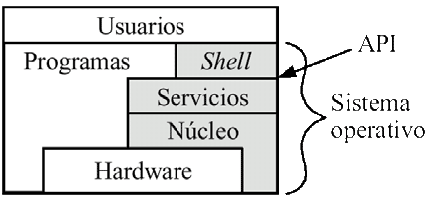
Sistema operativo
Un sistema operativo es un conjunto de programas que, aportando abstracciones, ponen el hardware de la máquina a disposición de los usuarios de un modo seguro y eficaz
Objetivos de un sistema operativo:
- Simplificar la utilización de la máquina
- Hacer un uso eficiente de los recursos de la máquina
- Controlar la ejecución de los programas de aplicación
Funciones del sistema operativo
El sistema operativo como interfaz de usuario:
- Intérprete de mandatos o shell (de texto o gráficos)
- Archivos de mandatos o shell scripts
El sistema operativo como gestor de recursos (Resuelve la competencia por los recursos):
- Asignación y recuperación de recursos
- Protección entre los usuarios
- Contabilidad y monitorización
El sistema operativo como máquina virtual. Ofrece servicios a los procesos de usuario mediante un conjunto de funciones (llamadas al sistema) que constituyen su interfaz de programación de aplicaciones (API):
- Creación de procesos/hilos para la ejecución de programas
- Órdenes de entrada/salida (E/S)
- Operaciones sobre archivos
- Detección y tratamiento de errores en el propio sistema operativo
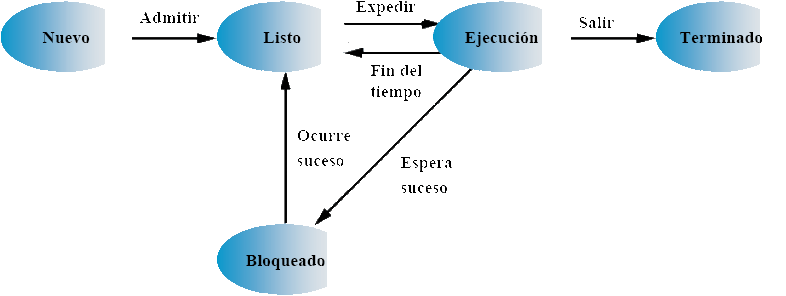
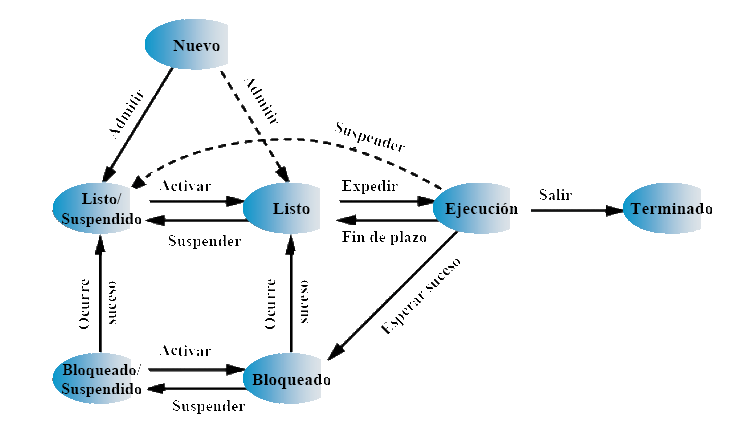
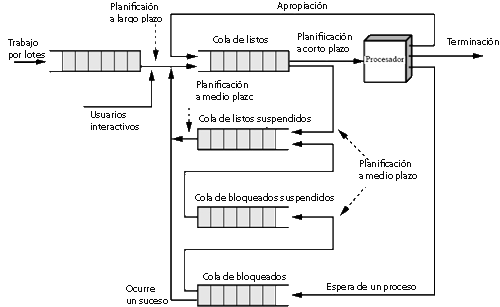
Multiprogramación y tiempo compartido
Dependiendo del número de procesos y de usuarios que puedan ejecutar simultáneamente, un sistema operativo puede ser:
- Monotarea o monoproceso
- Multitarea, multiproceso o multiprogramación
- Objetivo: maximizar la utilización del procesador
- Monousuario
- Multiusuario o tiempo compartido
- Objetivo: minimizar el tiempo de respuesta
Cuando un proceso necesite esperar a una instrucción de E/S, el procesador puede cambiar a otro proceso distinto, de este modo se consigue la multiprogramación
Para que sea posible:
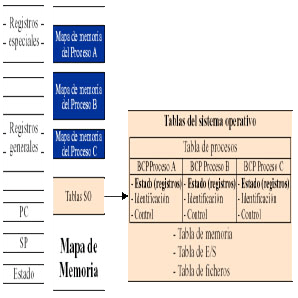
- Debe existir una gestión de memoria para repartir la memoria principal entre varios procesos
- Compartición multiplexada en espacio
- Debe existir una planificación para repartir el tiempo de la CPU entre los procesos que están en memoria
- Compartición multiplexada en tiempo
- Deben existir mecanismos de protección para el uso compartido de los recursos
- El sistema operativo asigna los dispositivos a los procesos y suministra las rutinas de E/S
Arquitectura Von Neumann
La arquitectura Von Neumann (modelo de Von Neumann o arquitectura Princeton), es una arquitectura para ordenadores basada en la descrita en 1945 por el matemático y físico John von Neumann y otros, en el primer borrador de un informe sobre el EDVAC (Electronic Discrete Variable Automatic Computer)
Describe la arquitectura para el diseño de un ordenador digital electrónico con partes que constan de una unidad de procesamiento que contiene una unidad aritmético lógica y registros del procesador, una unidad de control que contiene un registro de instrucciones y un contador de programa, una memoria para almacenar tanto datos como instrucciones, almacenamiento masivo externo, y mecanismos de entrada y salida
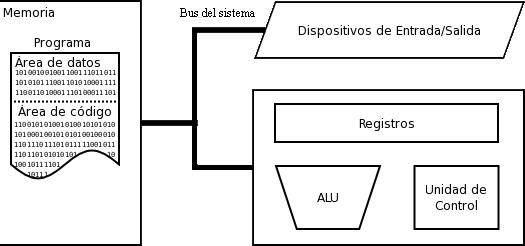
Registros del procesador
Contador de programa (CP)
Alberga la dirección de memoria principal de la siguiente instrucción que tiene que cargar la unidad de control
Registro de instrucción (RI)
Contiene una copia de la instrucción actual, obtenida de la memoria principal
El proceso hardware
Secuencia de lectura-ejecución:
- Lectura de la instrucción apuntada por el contador de programa (CP)
- Incremento del CP
- Ejecución de la instrucción Un computador sólo sabe repetir a gran velocidad esta secuencia
Se puede romper esta secuencia lineal modificando el valor del CP mediante:
- Instrucciones máquina de salto
- Interrupciones internas (interrupciones)
- Interrupciones externas (excepciones)
- Instrucción máquina trampa (trap)
Interrupciones externas
Conocidas comúnmente como interrupciones
Una interrupción es una señal recibida por la CPU, indicando que debe interrumpir su ejecución normal y pasar a ejecutar código específico para tratar esta situación
Es el mecanismo que utilizan los dispositivos para solicitar la atención de la CPU:
- Interrupciones periódicas de reloj
- Interrupciones de los dispositivos de E/S
Tratamiento de las interrupciones
Por hardware, ciclo de aceptación de interrupción:
- Salva el contexto del proceso en ejecución
- Contenido de algunos registros del procesador
- Eleva el nivel de ejecución del procesador (pasándolo a modo núcleo)
- Carga un nuevo valor en el CP (salta al sistema operativo)
Por software, el sistema operativo ejecuta una rutina tratamiento de la interrupción
Interrupciones internas
También denominadas excepciones, son sucesos inesperados internos al procesador:
- Desbordamiento aritmético
- División por cero
- Dirección inválida
- Intento de ejecutar una instrucción privilegiada
Tratamiento de las excepciones
La gestión de excepciones es similar a la de las interrupciones. Al detectarse la excepción, se transfiere el control al manejador de excepciones.La diferencia básica con las interrupciones es que las excepciones suelen tratarse en el espacio de usuario. El sistema operativo sólo las notifica
Instrucción trampa (trap)
Un proceso de usuario realiza una operación privilegiada mediante la instrucción trampa
Es una instrucción máquina de modo usuario que genera una excepción
Algunos la denominan interrupción software, o también, llamada al supervisor (SVC)
Es invocada por un proceso que está ejecutando en modo usuario y desea realizar una operación que requiere instrucciones privilegiadas
Cambia el bit de modo y bifurca hacia una posición fija del espacio del sistema
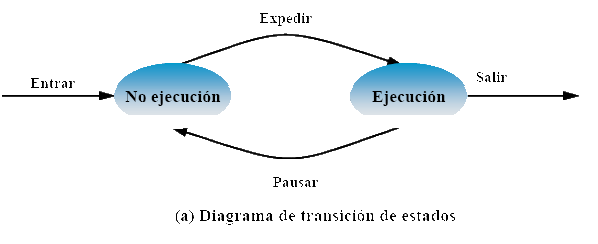
Modo dual de ejecución de la CPU
Llamamos instrucciones privilegiadas a aquellas instrucciones máquina que pueden potencialmente afectar a otros procesos:
- Operaciones de E/S
- Actualizar el reloj
- Desactivar las interrupciones
Controlando la ejecución de las instrucciones privilegiadas protegemos a otros procesos y al sistema operativo
Solución: Distinguir dos modos de ejecución de la CPU
Los procesadores actuales incluyen un bit de modo que modifica el nivel de ejecución:
- Modo usuario
- Sólo puede ejecutar instrucciones no privilegiadas
- El proceso sólo accede al espacio de usuario
- Modo supervisor o núcleo
- Se puede ejecutar cualquier instrucción máquina
- Se denomina núcleo (o kernel) al código del sistema operativo que se ejecuta en este modo
- Solamente el código del sistema operativo puede ejecutar en modo supervisor y tiene acceso tanto al espacio de sistema como al de usuario
Conclusión: El software de confianza del sistema operativo se ejecuta en modo supervisor y el resto del software se ejecuta en modo usuario
Llamadas al sistema
Las llamadas al sistema son procedimientos o funciones que ofrece el sistema operativo
Permiten a los procesos de usuario realizar operaciones privilegiadas
Se implementan a través de la instrucción trampa
- La instrucción trampa necesita de un operando para referenciar a una tabla del núcleo (tabla de trap)
Para ocultar los detalles de la instrucción trampa, el diseñador del sistema operativo proporciona una biblioteca de funciones de “resguardo”
- Los nombres de las funciones resguardo coinciden con los de las llamadas al sistema
- Cada función de resguardo contiene una instrucción trampa a la función del sistema operativo a través de la entrada correcta de la tabla del trap del núcleo
Interfaz de llamadas al sistema
Cada sistema operativo implementa un conjunto propio de llamadas al sistema que exporta a través de un interfaz de llamadas
Este conjunto de llamadas es el interfaz del sistema operativo con los programas de aplicación o API (Aplication Program Interface)
Los programas de aplicación invocan los servicios del sistema operativo llamando a las funciones definidas en el interfaz de llamadas al sistema
Las funciones están implementadas por varias partes del sistema operativo: gestor de procesos, gestor de memoria, gestor de dispositivos y gestor de archivos
Ejemplos:
- Estándar API POSIX en UNIX y Linux
- API Win32 en Windows
POSIX
Interfaz estándar de sistemas operativos portables de IEEE basado en UNIX
Objetivo: portabilidad de las aplicaciones entre diferentes plataformas y sistemas operativos
No es una implementación. Sólo define una especificación
Disponible en todas las versiones de UNIX y Linux
Windows 2000 ofrece un subsistema de POSIX
Características
Nombres de funciones cortos y en minúsculas
- fork
- read
- close
Las funciones normalmente devuelven 0 si se ejecutaron con éxito o -1 en caso de error
- Variable errno
Mayoría de los recursos gestionados por el sistema operativo se referencian mediante descriptores: número entero mayor o igual que cero
Win32
No es un estándar
Es un API totalmente diferente al estándar POSIX
Define los servicios ofrecidos por los sistemas Windows 95/98, Windows NT, Windows 2000 y Windows XP
Define funciones y servicios gráficos
Características
Nombre de las funciones largos y descriptivos
- GetFileAttributes
- CreateNamedPipe
Dispone de tipos de datos predefinidos
- BOOL
- DWORD
- TCHAR
Las funciones devuelven, en general, true si la llamada se ejecutó con éxito o false en caso contrario
Los recursos se manejan como objetos,referenciados mediante manejadores
Diseño de la estructura interna del sistema operativo
Monitor monolítico
Todo el sistema operativo se diseña como un único módulo compuesto por funciones que se pueden llamar unas a otras
Los procesos de usuario y los dispositivos de E/S se comunican a través del núcleo
Cuando se ejecuta código del monitor se deshabilitan las interrupciones
Ejemplos: MS-DOS, Windows XP, UNIX, Linux
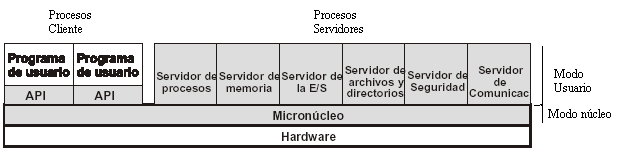
Micronúcleo
Algunas de las funciones del sistema operativo se implementan como procesos servidores de usuario
Las funciones del núcleo quedan reducidas al mínimo, con lo que la fiabilidad del sistema aumenta
Ejemplos: Minix, Mach, Windows NT