Encaminamiento
El encaminamiento, enrutamiento o ruteo, es la función de buscar un camino entre todos los posibles en una red de paquetes cuyas topologías poseen una gran conectividad
Dado que se trata de encontrar la mejor ruta posible y en consecuencia cuál es la métrica que se debe utilizar para medirla
La red debe encontrar una ruta mediante:
- Eficiencia
- Flexibilidad
Los conmutadores de la red se organizan en una estructura en árbol
El encaminamiento estático utiliza la misma aproximación todo el tiempo
El encaminamiento dinámico permite los cambios en el encaminamiento dependiendo del tráfico
Utiliza una estructura de relación de igual a igual para los nodos
Criterios de encaminamiento
Encaminamiento alternativo
Las posibles rutas entre dos centrales finales se encuentran predefinidas
Es responsabilidad del conmutador origen seleccionar el camino adecuado para cada llamada
Cada conmutador dispone de un conjunto de rutas prefijadas, en orden de preferencia
Un conjunto diferente de rutas preplanificadas en instantes distintos de tiempo
Dos tipos:
- Alternativo fijo
Sólo una secuencia de encaminamiento para cada pareja origen-destino - Alternativo dinámico
Conjunto diferente de rutas preplanificadas en instantes distintos de tiempo
Encaminamiento en redes de conmutación de paquetes
Uno de los aspectos más complejos y cruciales del diseño de redes de conmutación de paquetes es el relativo al encaminamiento
Características necesarias:
- Exactitud
- Simplicidad
- Robustez
- Estabilidad
- Imparcialidad
- Optimización
- Eficiencia
Criterios de rendimiento
Se utiliza para la elección de una ruta
Dos técnicas fundamentales:
- Elegir el camino con menor número de saltos: minimiza el consumo de recursos de la red
- Una generalización del anterior es el criterio del mínimo coste
- En caso de distintos costos por enlaces, se tomará aquel camino que sea el del mínimo coste
- Si cada nodo tiene igual coste se puede generalizar este criterio buscando el camino de menor número de saltos
Instante y lugar de decisión
- Instante
- Paquete o datagrama
Si cambian los costos, el paquete siguiente puede seguir una ruta diferente, de nuevo determinada por cada nodo a lo largo del camino - Circuito virtual
Cada nodo recuerda la decisión de encaminamiento tomada cuando se estableció el circuito virtual, de modo que se limita a transmitir los paquetes sin tomar decisiones nuevas
- Paquete o datagrama
- Lugar
- Encaminamiento distribuido
- Se lleva a cabo por cada nodo
- Es el más robusto
- Encaminamiento centralizado
- Encaminamiento desde el origen
- Encaminamiento distribuido
Fuente de información de la red y tiempo de actualización
Las decisiones de encaminamiento se suelen tomar en base al conocimiento de la red, la carga y el coste de los enlaces (pero no siempre como por ejemplo con inundaciones y encaminamiento aleatorio)
- Encaminamiento distribuido
- Los nodos hacen uso de información local (coste asociado a cada enlace de salida)
- Pueden utilizar información de los nodos adyacentes (congestión entre ellos)
- Pueden obtener información de todos los nodos de una potencial ruta de interés
- Encaminamiento central
- Recopilar información de todos los nodos
- Tiempo de actualización
- Cuando los nodos tienen información actualizada de la red
- Para una estrategia de encaminamiento estático, la información no se actualiza nunca
- Para una técnica adaptable, la actualización se lleva a cabo periódicamente
Estrategias de encaminamiento ARPANET
Primera generación: 1969
- Algoritmo adaptable distribuido
- Estimación de los retardos como criterio de funcionamiento
- Algoritmo de Bellman-Ford
- Cada nodo intercambia su vector de retardo con todos sus vecinos
- Tabla de encaminamiento actualizada basándose en la información de entrada
- No tiene en cuenta la velocidad de la línea, sino la longitud de la cola
- La longitud de la cola no es una buena medida del retardo
- Responde lentamente a la congestión
Segunda generación: 1979
- Se hace uso del retardo como criterio de rendimiento
- El retardo se mide directamente
- Algoritmo de Dijkstra
- Es bueno ante cargas bajas o moderadas
- Ante cargas altas, existe poca correlación entre los retardos indicados y los experimentados
Tercera generación: 1987
- Cambian las estimaciones del coste del enlace
- Medida del retardo medio en los últimos 10 segundos
- Se normaliza en base al valor actual y a los resultados previos
Estrategias de encaminamiento
Encaminamiento estático
Una única ruta permanente para cada par de nodos origen-destino en la red
Se determinar las rutas utilizando cualquiera de los algoritmos de encaminamiento de mínimo coste
Las rutas son fijas, al menos mientras lo sea la topología de la red
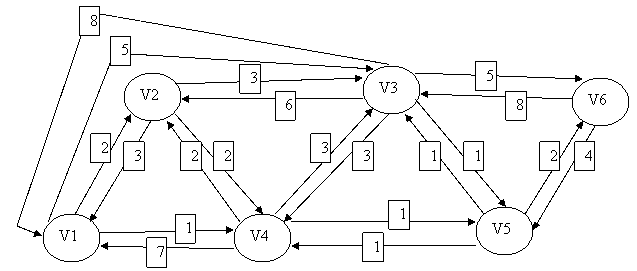
Ejemplo de encaminamiento estático
Matriz de encaminamiento central
{\tiny\text{Nodo destino}}\overset{\text{Nodo origen}}{\begin{pmatrix}& 1& 2& 3& 4& 5& 6 \\ 1& & 1& 5& 2& 4& 5 \\ 2& 2& & 5& 2& 4& 5 \\ 3& 4& 3& & 5& 3& 5 \\ 4& 4& 4& 5& & 4& 5 \\ 5& 4& 4& 5& 5& & 5 \\ 6& 4& 4& 5& 5& 6 \\ \end{pmatrix}}
| Tabla del nodo 1 | |
| Destino | Nodo siguiente |
| 2 | 2 |
| 3 | 4 |
| 4 | 4 |
| 5 | 4 |
| 6 | 4 |
| Tabla del nodo 2 | |
| Destino | Nodo siguiente |
| 1 | 1 |
| 3 | 3 |
| 4 | 4 |
| 5 | 4 |
| 6 | 4 |
| Tabla del nodo 3 | |
| Destino | Nodo siguiente |
| 1 | 5 |
| 2 | 5 |
| 4 | 5 |
| 5 | 5 |
| 6 | 5 |
| Tabla del nodo 4 | |
| Destino | Nodo siguiente |
| 1 | 2 |
| 2 | 2 |
| 3 | 5 |
| 5 | 5 |
| 6 | 5 |
| Tabla del nodo 5 | |
| Destino | Nodo siguiente |
| 1 | 4 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 6 | 6 |
| Tabla del nodo 6 | |
| Destino | Nodo siguiente |
| 1 | 5 |
| 2 | 5 |
| 3 | 5 |
| 4 | 5 |
| 5 | 5 |
Inundaciones
No precisa de ninguna información sobre la red. Un nodo origen envía un paquete a todos sus nodos vecinos. Los nodos vecinos, a su vez, lo transmiten sobre todos los enlaces de salida excepto por el que llegó. Finalmente, llegará un número de copias al destino
Cada paquete contiene un identificador único, por lo que se pueden descartar los duplicados. De esta forma, una técnica sería que los nodos puedan recordar la identidad de los paquetes que han retransmitido con anterioridad, de manera que se evitan las cargas de la red
Otra técnica más sencilla es que se pueda incluir un campo de cuenta de saltos en cada paquete, un tiempo de vida donde cada vez que un nodo transmite un paquete, decrementa la cuenta en 1, de modo que cuando el contador alcanza el valor cero de elimina el paquete de la red
Propiedades
- Se prueban todos los posibles caminos entre los nodos origen y destino. Lo que nos ofrece robustez
Ejemplo: el envío de un mensaje de alta prioridad para garantizar la recepción del paquete - Al menos una copia del paquete a recibir en el destino habrá usado una ruta de menor número de saltos. Podría emplearse inicialmente para establecer la ruta para un circuito virtual
- Se visitan todos los nodos. Puede resultar útil para llevar a cabo la propagación de información relevante para todos los nodos (por ejemplo, una tabla de encaminamiento central)
Ejemplo de inundación
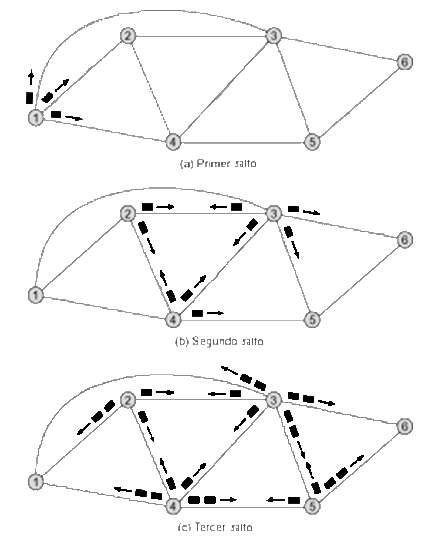
Encaminamiento aleatorio
Un nodo selecciona un único camino de salida para retransmitir un paquete entrante. La selección se puede hacer de forma aleatoria o alternada
Una mejoría es que se pueda seleccionar la ruta de salida de acuerdo con el cálculo de probabilidades
No necesita el uso de información sobre la red. La ruta no corresponderá en general con la de mínimo coste ni con la de menor número de saltos. Tiene menos tráfico que la de inundaciones pero es igualmente sencilla y robusta.Un nodo selecciona un único camino de salida para retransmitir un paquete entrante. La selección se puede hacer de forma aleatoria o alternada
Una mejoría es que se pueda seleccionar la ruta de salida de acuerdo con el cálculo de probabilidades
No necesita el uso de información sobre la red. La ruta no corresponderá en general con la de mínimo coste ni con la de menor número de saltos. Tiene menos tráfico que la de inundaciones pero es igualmente sencilla y robusta
Encaminamiento adaptable
Prácticamente en todas las redes de conmutación de paquetes se utiliza algún tipo de técnica de encaminamiento adaptable
Las decisiones de encaminamiento cambian en la medida que lo hacen las condiciones de la red:
- Fallos
- Congestión
Requiere información acerca del estado de la red presentando desventajas:
- Las decisiones son más complejas: mayor coste de procesamiento en los nodos de la red
- Es necesario que los nodos intercambien información acerca del estado y del tráfico de la red: mayor tráfico y degradación de las prestaciones de la red
- La reacción demasiado rápida puede provocar oscilación o ser demasiado lenta para ser relevante
Ventajas del encaminamiento adaptable
- Mejora de las prestaciones
- Resulta de ayuda en el control de la congestión
- Sistema complejo: Puede que no se cumplan los beneficios teóricos
Clasificación
Clasificación realizada de acuerdo con la fuente de información
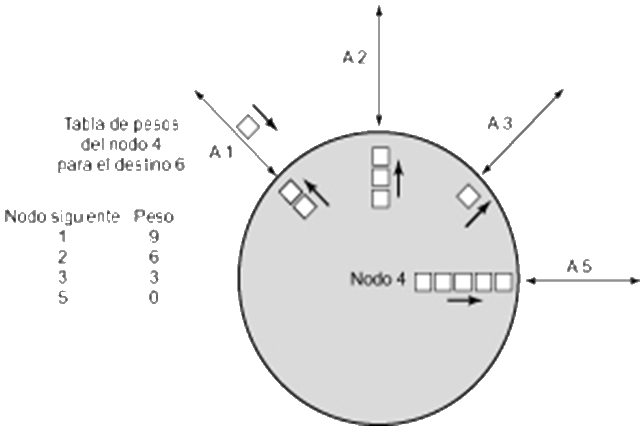
- Local (aislada)
- Encaminar el paquete hasta el enlace de salida con la cola más corta
- Puede incluir un peso para cada destino. Se utilizan raramente, puesto que no explotan con facilidad la información disponible
- Nodos adyacentes
- Todos los nodos
Ejemplo de encaminamiento adaptable aislado